Local LLM Writing and Prose Benchmark: The Right Tool (Part 4)
Part 4 of the local LLM network test. Evaluating six local AI models against Haiku on unstructured prose, session logs, and incident narratives.


The Writing Test - What Models Can't Fake
Parts 1–3 measured code generation, YAML structure, and GPU throughput. Every task had a machine-verifiable answer. Part 4 doesn't. The tasks are prose. Synthesize this log, narrate that incident, write a change log entry with these fields. No auto-checker validates a well-structured paragraph.
This is the benchmark that tests what models do when the output format can't be unit-tested.
What I Changed
One new model: Mistral Nemo 12B (mistral-nemo:latest, 7.1 GB Q4, 4.2 tok/s on GPU). I have been comparing Llama 3.1 8B as the incumbent general-purpose 8B. Part 4 adds Mistral Nemo as the contender. It is a 12B model built for instruction following, not code generation. The question is whether its training focus shows on writing tasks.
All six local models ran on the same hardware with the same GPU configuration as Part 3. No changes to quantization, runtime, or Ollama configuration.
The Four Tasks
Writing tasks drawn from actual autonomous network workloads. Not hypothetical. These are things the system does or needs to do.
W1: Session Log Digest. 24 real SLA breach events from the autonomous session log. Latency: 9.57–11.50ms against a 5.0ms threshold, no recovery, 24-minute window. Task: one paragraph, 100 words maximum, shift-handoff quality. The test: can the model synthesize 24 breach lines into a usable summary without enumerating them?
W2: BGP Incident Narrative. The same BGP event log from T2, different task. T2 asked for triage (classify events). W2 asks for a post-incident narrative in three paragraphs: what happened and when, scope and impact, root cause and resolution. The test: does the model get the timeline right, scope the impact correctly, and stay within evidence?
W3: Lab Status Brief. A composite snapshot of current lab state. L3 latency at 10.70ms, 24 breaches over 24 minutes, BGP fabric all-established, srl2 prefix pressure at 487/500 (97.4%). Task: exactly three bullets, each starting with a status tag in brackets ([BREACH], [STABLE], [ACTION]). The test: strict format compliance under constraint.
W4: Change Log Entry. Context: the Hold_Timer_Expired incident at 09:14, 66-second reconvergence. Planned change: reduce hold-timer from 90s to 30s across all fabric BGP sessions. Task: five required fields. COMPONENT, WHAT, WHY, EXPECTED IMPACT, ROLLBACK. Each one sentence. The test: structured prose with explicit incident linkage.
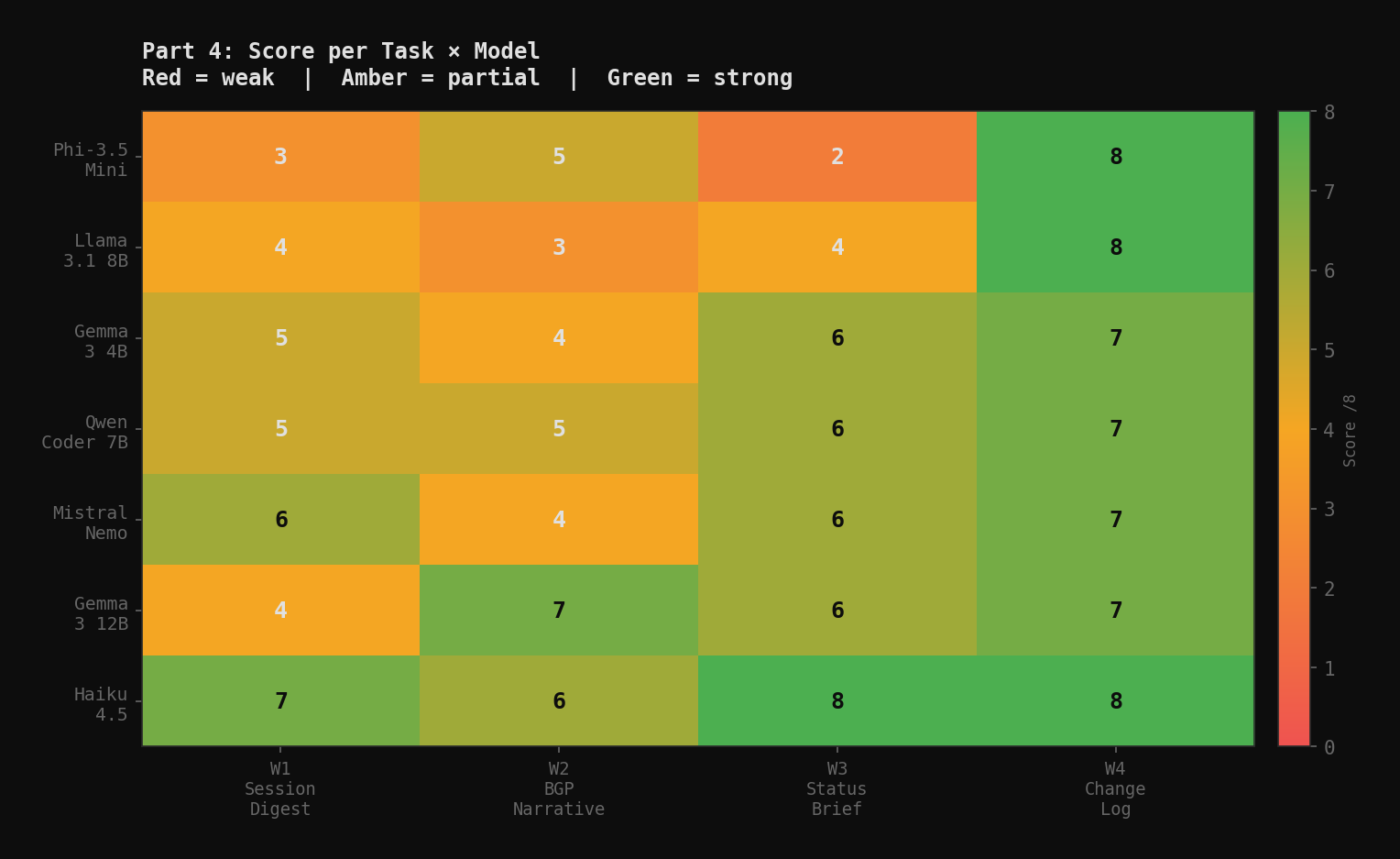
Scoring: 4 dimensions per task, 0–2 each, 8 points per task, 32 total. Manual scoring. No auto-checker validates prose quality.
The Scores
| Model | W1/8 | W2/8 | W3/8 | W4/8 | Total/32 |
|---|---|---|---|---|---|
| Phi-3.5 Mini | 3 | 5 | 2 | 8 | 18 |
| Gemma 3 4B | 5 | 4 | 6 | 7 | 22 |
| Qwen 2.5 Coder 7B | 5 | 5 | 6 | 7 | 23 |
| Llama 3.1 8B | 4 | 3 | 4 | 8 | 19 |
| Mistral Nemo 12B | 6 | 4 | 6 | 7 | 23 |
| Gemma 3 12B | 4 | 7 | 6 | 7 | 24 |
| Claude Haiku 4.5 | 7 | 6 | 8 | 8 | 29 |
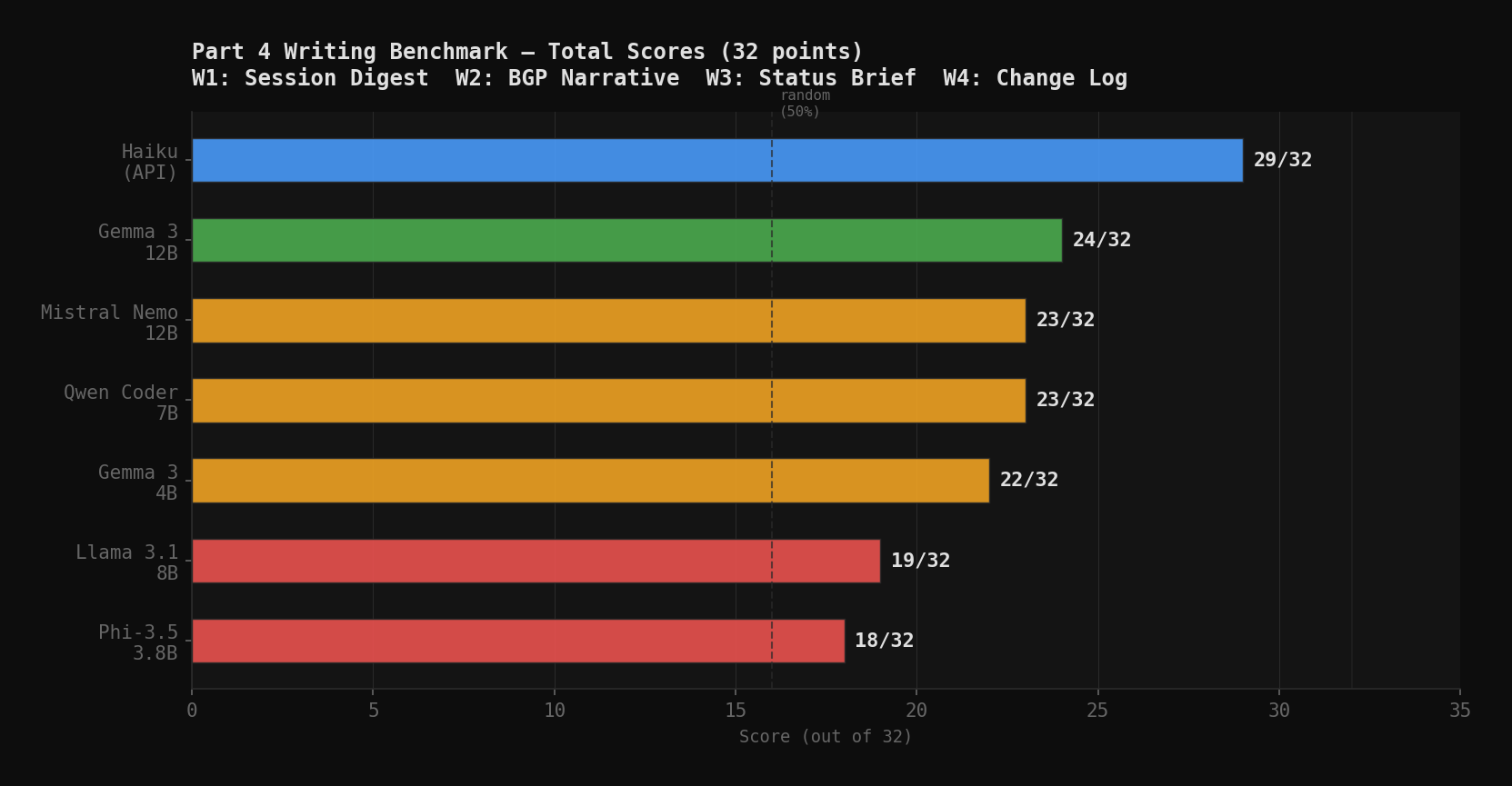
Three findings dominate this table.
Finding 1: Gemma 3 12B Leads Local Models
Gemma 3 12B. The model that couldn't reliably pass T3 across three runs scored 24/32 on writing tasks. That puts it 1 point ahead of the next local contenders and 5 points ahead of Llama 3.1 8B.
The W2 score explains it. On the BGP incident narrative, Gemma 12B got every timestamp right, correctly characterized the scope (srl1/10.0.0.2 primary fault, srl2 prefix-limit as secondary, srl3 route-refresh as informational), and stayed strictly within log evidence for the causal chain. That is 7/8. The best W2 score among all local models.
Gemma 3 12B output on W2 (excerpt):
On 2026-05-22, a BGP peering disruption occurred between srl1 and peer 10.0.0.2. The peer relationship initially established at 09:12:04Z with a hold time of 90 seconds and an AS number of 65002. Subsequently, at 09:14:22Z, srl1 sent a NOTIFICATION to the peer indicating a "Hold_Timer_Expired" error... The root cause of the brief peering disruption between srl1 and 10.0.0.2 remains undetermined based on available log data; the Hold_Timer_Expired notification suggests a potential timing issue or brief network blip affecting the keepalive exchange.
That last sentence is exactly the right epistemic posture. It names the cause class without fabricating one.
The same model failed T3 (structured YAML generation) twice before passing it on run 3. T3 tests structured output precision. W2 tests narrative reasoning. These are different skills. A benchmark that only tests code generation would have written off Gemma 3 12B as a marginal performer. Part 4 shows it is the best local prose model on this hardware.
Finding 2: Mistral Nemo Didn't Move the Field
Mistral Nemo tied Qwen 2.5 Coder 7B at 23/32. That is the clearest verdict in the series.
Mistral Nemo is a 12B general-purpose model trained for instruction following. Qwen 2.5 Coder is a 7B model specialized for code generation. On prose tasks, the supposed generalist advantage didn't materialize. They produced nearly identical total scores despite the 5B parameter gap.
Where Mistral Nemo was better: W1, where it synthesized correctly (no event enumeration, 6/8). Where it was worse: W2, where it used bold markdown headers as paragraph dividers (deducted for prose quality) and made a timing calculation error (cited 82 seconds for a 138-second interval between establishment and IDLE). W4: its rollback was too vague ("Restore hold_timer back to 90s". No mechanism, no scope).
Where Qwen was better: W4, where it named both improvement and risk in the impact assessment with one clean line each. Where it was worse: W1, where it counted 30 breach events and 12 minutes instead of 24 events and 24 minutes. The coder-specialized model is more concise but less accurate on raw data summarization.
The Mistral Nemo vs Llama 3.1 8B comparison is unambiguous: Mistral Nemo 23, Llama 8B 19. Speed-wise, Mistral Nemo runs at 4.2 tok/s on W1 (cold load, long prompt) and 6.7–7.1 tok/s on W2-W4. Roughly the same throughput range as Gemma 3 12B. Llama 3.1 8B runs at 12–13 tok/s throughout. If speed is the constraint, Llama 8B is faster and competitive at code (Parts 1–3). If quality is the constraint, Mistral Nemo edges it on prose. But Gemma 3 12B does better at similar speed and was already in the lineup.
Finding 3: Llama 3.1 8B Falls Apart on Narrative
Llama 3.1 8B scored 19/32. The low score comes from specific, repeatable failures.
W2 had a mathematical error. The model wrote: "The session was eventually re-established 23 minutes later, at 09:15:28Z." The reconvergence was 66 seconds. Just over one minute. This isn't a rounding error. It is the model generating a plausible-sounding duration that isn't in the log. The correct duration is derivable from the timestamps it cited correctly.
W2 also dropped the entire secondary storyline. The srl2 prefix-limit at 487/500 (97.4%) was in the log. Llama's scope paragraph: "The BGP disruption primarily affected nodes srl1 and its peer 10.0.0.2. No other peers or services were directly impacted." That is factually wrong given what the log contains.
W3 had a format failure. The third bullet read [WARNING]: prefix pressure on srl2. The task specified [ACTION] for the third bullet. The model's third bullet was a status observation, not an action. An operator reading that brief couldn't determine what to do next.
Llama 3.1 8B scored 8/8 on W4. The structured format bailed it out. When the task has five labeled fields and one sentence per field, Llama performs as well as any model in the series. When the task requires reasoning over a narrative with an implicit structure, it fabricates.
W4: The Equalizer
W4 produced the tightest spread in the series. Phi-3.5 Mini and Llama 3.1 8B scored 8/8. Gemma 3 4B, Qwen Coder, Mistral Nemo, and Gemma 3 12B all scored 7/8. The losses were narrow. One dimension each, mostly rollback vagueness.
The pattern: explicit format specification eliminates most model failure modes. When the prompt says "five fields, exact labels, one sentence each," every model produced a usable change log entry. This includes the 3.8B Phi-3.5 Mini.
This has an architectural implication. Prose tasks that arrive with a defined schema (change logs, status templates, structured summaries) are tractable for even the smallest models. Prose tasks that require the model to impose its own structure (narratives, open-ended summaries) produce much wider quality variance.
The voice loop is the extreme version. Spoken responses have no format spec at all. The model decides length, structure, and level of detail. That is where the capability gap between models, and between local and API, is largest.
W1: The Hardest Test
Every local model miscounted the breach events. The log contains 24 distinct entries. Results:
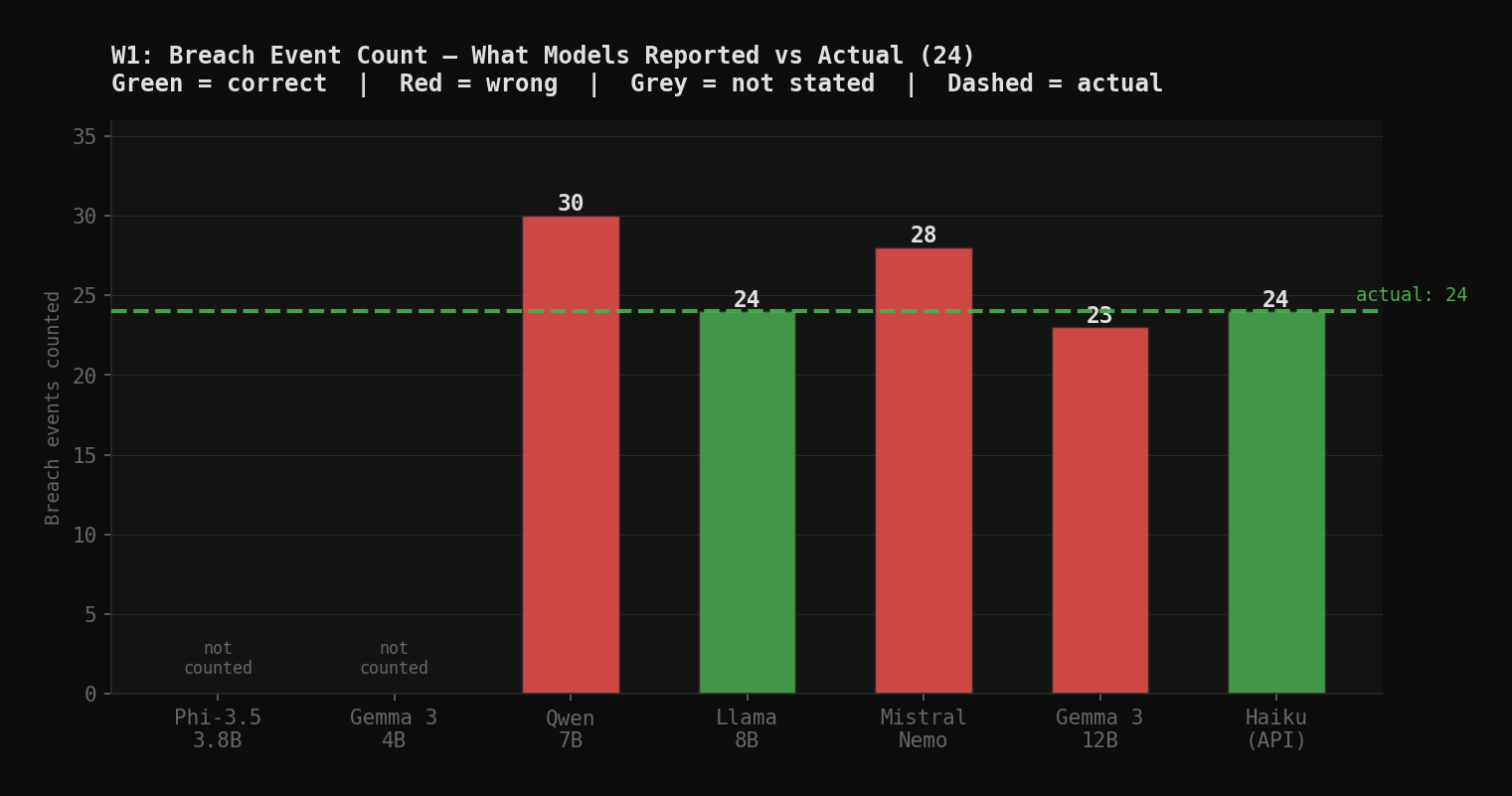
| Model | Count given | Actual |
|---|---|---|
| Phi-3.5 Mini | not stated | 24 |
| Gemma 3 4B | not stated | 24 |
| Qwen 2.5 Coder 7B | 30 | 24 |
| Llama 3.1 8B | "exceeding 24" | 24 |
| Mistral Nemo 12B | 28 | 24 |
| Gemma 3 12B | 23 | 24 |
| Claude Haiku 4.5 | 24 ✓ | 24 |
The counting failure is consistent enough to be a category finding, not a model quirk. The log format may be part of it. The first session end summary appears embedded between the second and third breach entries. A model that reads the log sequentially may treat the summary as a breach, or recount entries differently depending on how it tokenizes the block.
More interesting is what happens after the count. Mistral Nemo (28 events, wrong) wrote a coherent synthesis that characterized the pattern correctly. Stable floor, no recovery, AI prediction alignment. Qwen Coder (30 events, wrong) also synthesized without enumeration. Gemma 12B (23 events, wrong) added an unrequested preamble but the paragraph body was accurate otherwise.
The synthesis quality doesn't track with counting accuracy. These are separable capabilities. The ability to summarize a pattern versus the ability to count raw data entries.
Haiku on Writing Tasks
Haiku scored 29/32. The four-point deficit is spread across three tasks.
W1 lost a point on format. Haiku added a bold header **Shift Handoff Summary** before the paragraph. The prompt said one paragraph. The header is a reasonable instinct. It would make the handoff more readable in a document. But it violates the literal spec. This is a judgment call. In production, you'd probably want the header.
W2 lost two points. The duration calculation: Haiku wrote "2 minutes and 24 seconds from...09:14:22...until...09:15:28". The actual interval is 66 seconds. One minute and six seconds. The timestamps are correct. The arithmetic is wrong. Haiku also characterized the srl2 prefix-limit as "normal operational activity," which undersells a 97.4% utilization warning. That is the right call for srl3's route-refresh (genuinely informational). It is the wrong call for srl2 at 97.4%.
W3 was a perfect 8/8. The bullets:
• [BREACH] L3 latency at 10.70ms exceeds 5.0ms threshold with 24 consecutive events over 24 minutes and no recovery trend observed.
• [STABLE] BGP fabric operational with all 4 peers established and zero active faults despite latency condition.
• [ACTION] Investigate srl2 prefix capacity at 487/500 (97.4%) as root cause of sustained L3 latency elevation.
That is what "3 bullets that an operator can act on" looks like.
W4 was also a perfect 8/8. Haiku's WHY field explicitly named the 66-second reconvergence and the date/time of the incident. The ROLLBACK field named all four nodes and two rollback mechanisms. No other model was that specific on rollback.
The Routing Verdict from Part 4
The voice loop conclusion from Part 3 doesn't change. Writing tasks are background operations. Session digests don't need to arrive in under 8 seconds. The throughput numbers from Part 4 are consistent with Part 3. 4B-class models are still the only local voice-viable option at 27–28 tok/s. The 12B models remain background-only at 4–7 tok/s.
What changes is the background lane ranking.
Before Part 4, Qwen 2.5 Coder 7B was the clear local leader. It passed T3 most reliably. It was fast enough for background work. For code and YAML tasks, that standing holds. For prose tasks, Gemma 3 12B takes the lead.
The operational split emerging from the local series:
| Task class | Recommended local model | Rationale |
|---|---|---|
| Code generation / YAML | Qwen 2.5 Coder 7B | T3 best pass rate, 14 tok/s |
| Prose / summarization | Gemma 3 12B | 24/32 prose, 7 tok/s |
| Voice response | Gemma 3 4B or Phi-3.5 Mini | GPU-resident, 5–6s response |
Notice what is missing from this table. Claude Haiku 4.5 scored 29/32, running at 2–6s with no VRAM constraints. It is the most capable model tested. But it is an API. It is a tether. It remains the calibration standard, not a local routing option.
Mistral Nemo doesn't displace any of those local slots. It ties Qwen Coder on prose, runs at 6–7 tok/s on sustained tasks (matching Gemma 3 12B), and offers no quality advantage over existing models for this workload. The model's reputation for instruction following didn't show up in the numbers. It may perform differently on longer-form tasks, but this benchmark didn't find evidence to justify the added size and latency.
What I Have Found
Four runs. The table at the end of Part 4 looks like this:
- Claude Haiku 4.5 remains the absolute ceiling of the test. No local model approaches it on speed or reliability. It also requires an external tether to function.
- Qwen 2.5 Coder 7B owns the background code slot. T3 pass rate and 14 tok/s make it the right tool for topology generation and scripting.
- Gemma 3 12B owns the background prose slot. Best local narrative reasoning, best scope accuracy, best fact adherence in W2.
- Gemma 3 4B and Phi-3.5 Mini own the voice slot on GPU hardware. 27–28 tok/s, VRAM-resident, borderline viable.
- Llama 3.1 8B is the odd model out. It performs at the pack average on code tasks and underperforms on prose. The 8B parameter point has better options on either side.
- Mistral Nemo 12B doesn't add a new slot. It matches Qwen Coder on prose and runs slower than Gemma 12B. It is a capable model that arrived in a field where its capabilities are already covered.
Part 5: the routing decision. No new benchmark runs. One question. Given everything Parts 1–4 measured, which model routes to which task in a production deployment, and where does the local/API boundary actually sit?
The Right Tool is a field series on local LLM deployment in a live network lab. Part 1 established the CPU baseline. Part 2 corrected the test design. Part 3 completed GPU characterization. Part 4 evaluated prose tasks and introduced Mistral Nemo. Part 5 makes the routing call.